.Collaborative PROJECT
Redesigning Voice Mask for Dynamic Jaw Movement
GOAL

.THE PROBLEM
The Flawed Design
The original Universal Voice (UV) Singing Mask fails both functionally and in how it fits users, leading to unreliable performance during vocal training. This project addresses those issues by redesigning the mask to move with the jaw and by replacing the arbitrary sizing system with a data-driven one
Functionality
The rigid anesthesia-based mask cannot adapt to the 45–75 mm vertical jaw opening and lateral cheek movement required for singing, so the airtight seal breaks during real vocal use.
When the seal fails, often around the cheeks and nasal bridge, the mask can no longer support effective SOVT exercises or reliably improve breathing control, power, or tension reduction.
Sizing problem
The original S/M/L sizing, loosely mapped to child/woman/man and anesthesia mask sizes, was based on assumptions about gendered facial proportions rather than real anthropometric data, leading to poor fit and seal inconsistencies.
Because the sizing system was based on medical anesthesia mask sizes, it conflicted with the core requirement of maintaining an airtight seal for a wide range of singers

Image of Voice mask,
Source : universal-voice.com
.Solution
MASK REDESIGN.
The mask was redesigned from a rigid, static device into a dynamic hybrid structure that moves with the face while maintaining an airtight seal.



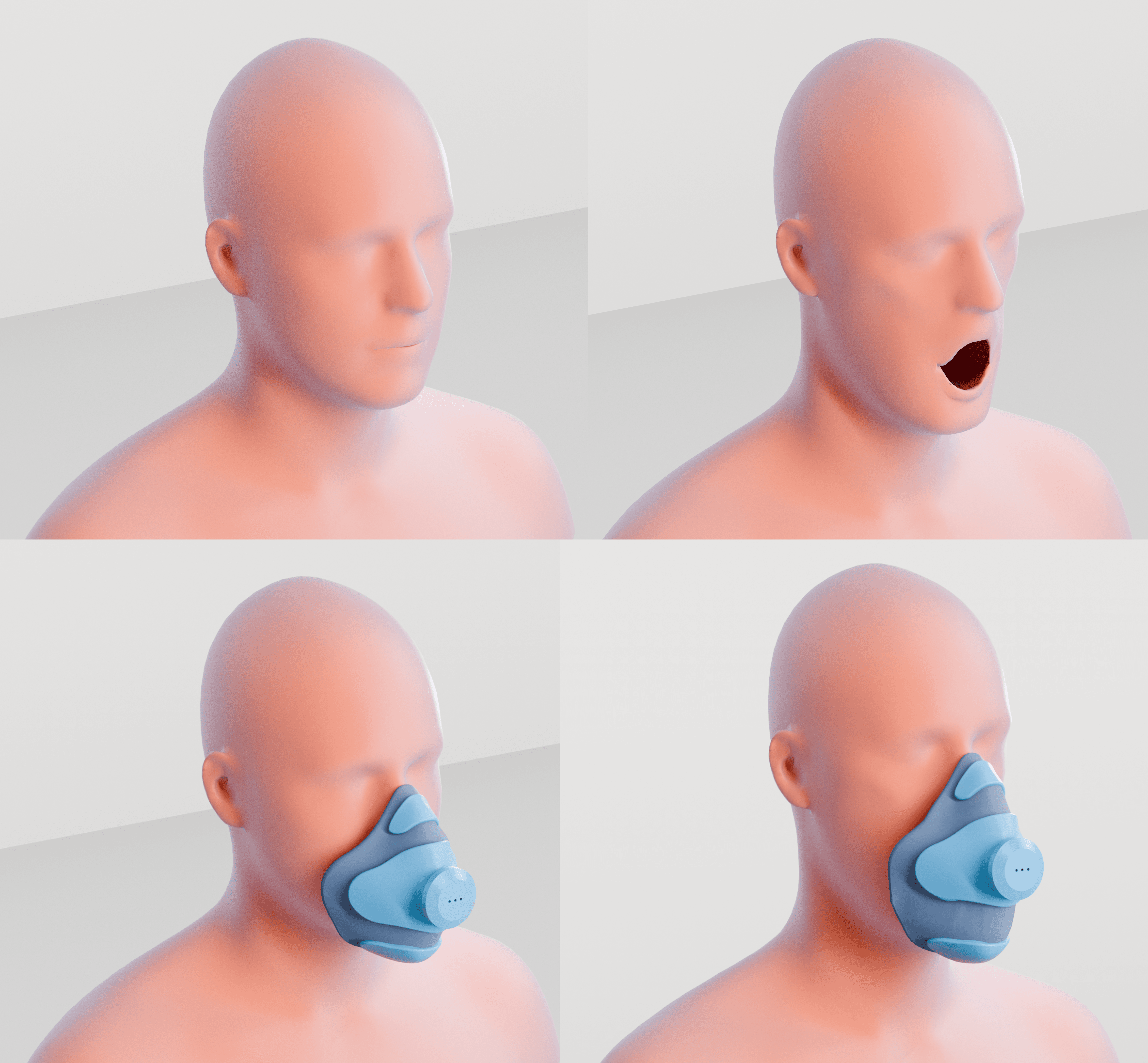
Hybrid construction
The design separates rigid support from flexible sealing components, similar to high‑performance respirators, so structure and comfort can be optimized independently.
Skeletal support frame
A minimal rigid frame anchors the mask at the nose and jaw, stabilizing it and distributing pressure even as the face and mandible move.
Flexible silicone seal
Most of the contact surface is a soft silicone seal that adapts to large jaw movements and soft‑tissue shifts while keeping constant contact and a reliable seal for SOVT exercises.
Modular back‑pressure control
Interchangeable caps at the exhalation/valve area let users adjust resistance and back‑pressure for different vocal training routines.
.RENDERS






.DATA-CENTRIC PERSONALISATION
PERSONALISATION.
The new data-driven sizing system for the Universal Voice Singing Mask was developed through a five-step process, from defining the target users and data to optimizing size groups with a Python tool and finalizing six size categories. This approach combines existing anthropometric data with new movement measurements to ensure both fit and seal during singing.
Target group and data source
The system is optimized for adults aged 18–30, a key period for vocal training, using the mixed-gender CEASAR (NL) anthropometric dataset from DINED as the primary data source.
Key facial dimensions
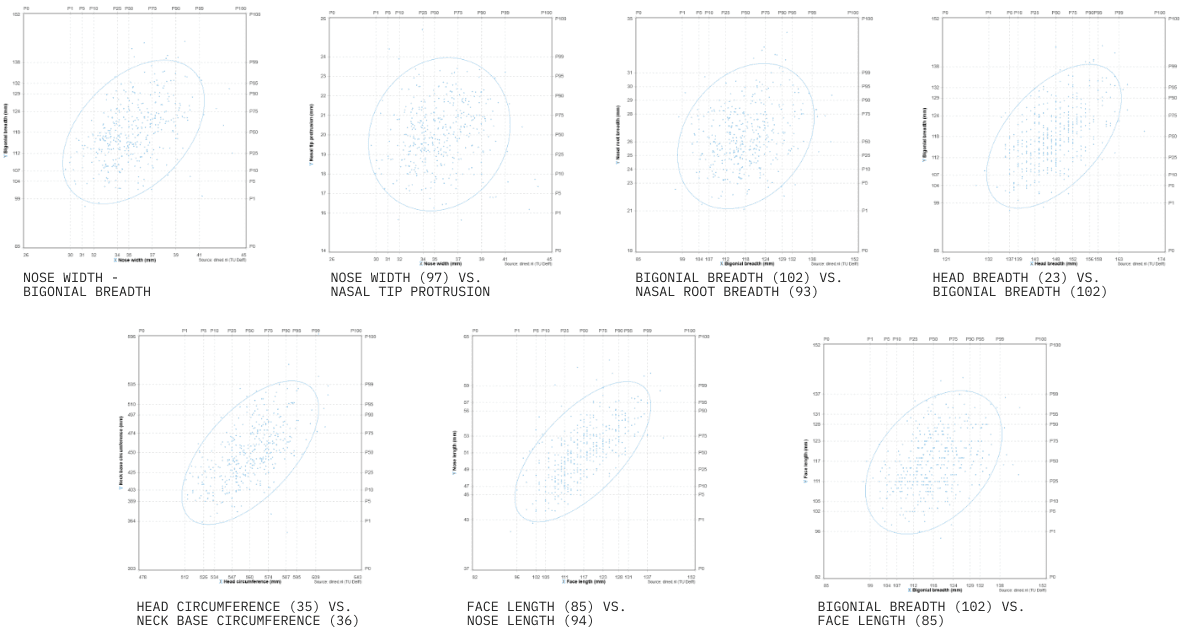
Because the mask seals around the lower face and jaw, the analysis focused on dimensions such as bigonial breadth (jaw width) and face length (vertical height). Bigonial breadth and face length were chosen as the two independent axes for sizing, as they strongly predict fit and do not correlate with each other.
Adding the Jaw movement measurements
Existing datasets did not include how mouth opening affects these dimensions, which is critical for maintaining a seal during extreme jaw positions like an “opera O.” To fill this gap, nose-to-chin distances (mouth closed and exaggerated open “O”) were measured on 9 participants (ages 18–30, 5 female, 4 male), linking vertical movement to the static anthropometric data.
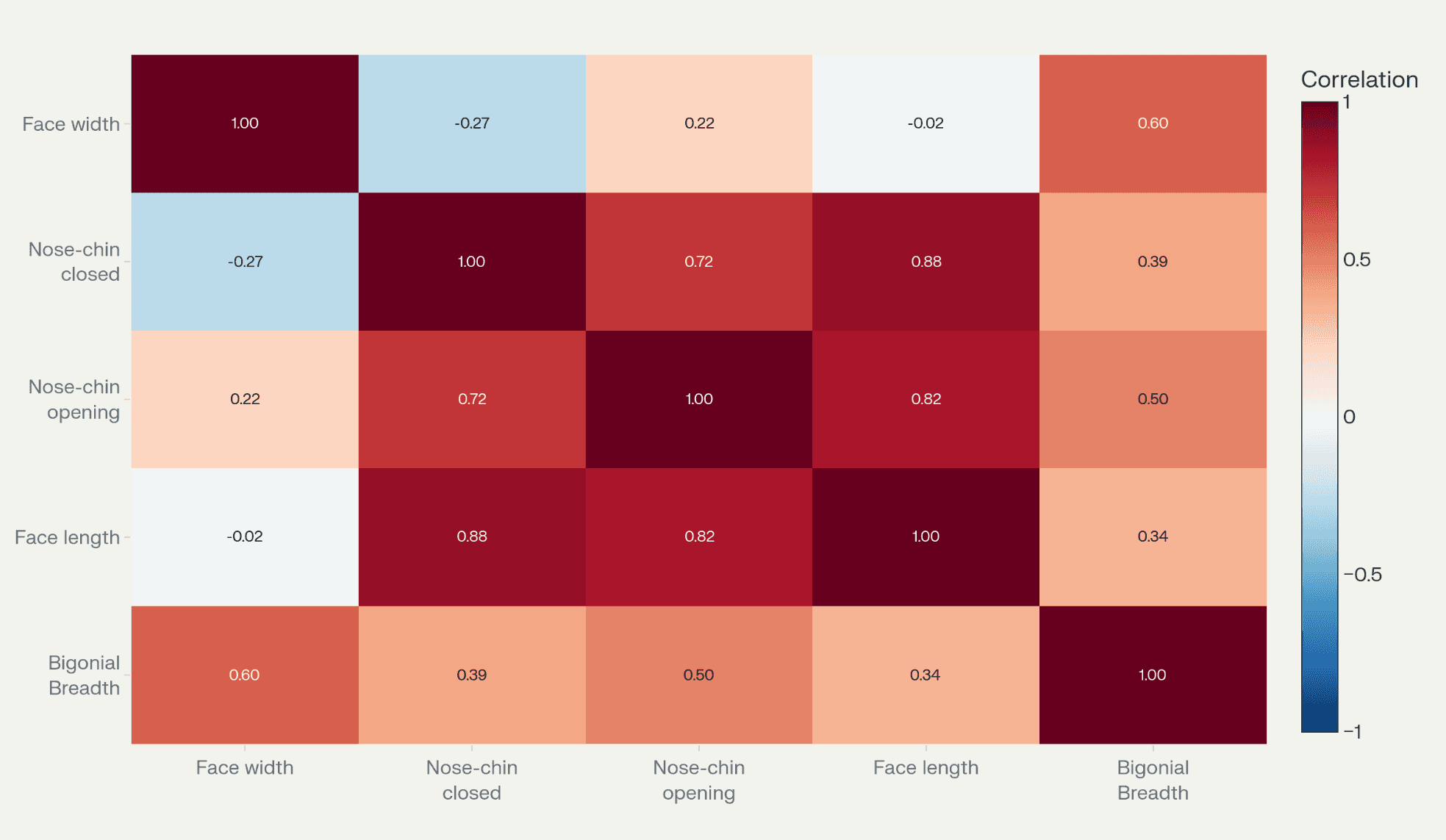
Co-relation Matrix from our own measurements
Python Script for finding the best grouping for the size
Python-based optimization
A custom Python script was built to define size groups, their boundaries, and ideal design centroids based on user-defined inputs: number of sizes and target population coverage (for example, 95%). The script removes outliers, divides the data into flexible “size boxes,” calculates a Misfit Cost (sum of distances from out-of-box data points to the nearest box edge), and computes a centroid for each box as the ideal design point.
Final six-size matrix
The script was run for 4, 6, and 8 size groups at 95% coverage, yielding Misfit Costs of 70.30, 65.88, and 70.56, respectively; six sizes provided the best balance of coverage and practicality. Final boundaries were refined in DINED, resulting in six size categories—Narrow-Small, Medium-Small, Wide-Small, Narrow-Long, Medium-Long, and Wide-Long—defined by Measurement A (width: bigonial/bitragion breadth) and Measurement B (height: face length). This structured, data-first method aligns with recommended practices for clear, concise technical communication in design case studies
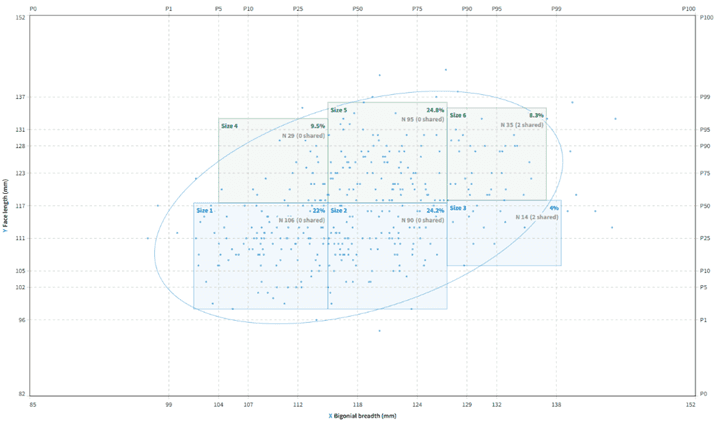
Boxes in Dined
.ValiDATION AND the SIZING
VALIDATION.
The New Sizing System
The new sizing system defines six data-driven size groups for the Universal Voice Singing Mask, optimized for users aged 18–30 and replacing the original arbitrary S/M/L scheme. It is based on two independent facial dimensions from the CEASAR (NL) dataset: Bigonial Breadth (width) and Face Length (height), and was generated with a Python optimization algorithm targeting about 95% population coverage and airtight fit for vocal training.
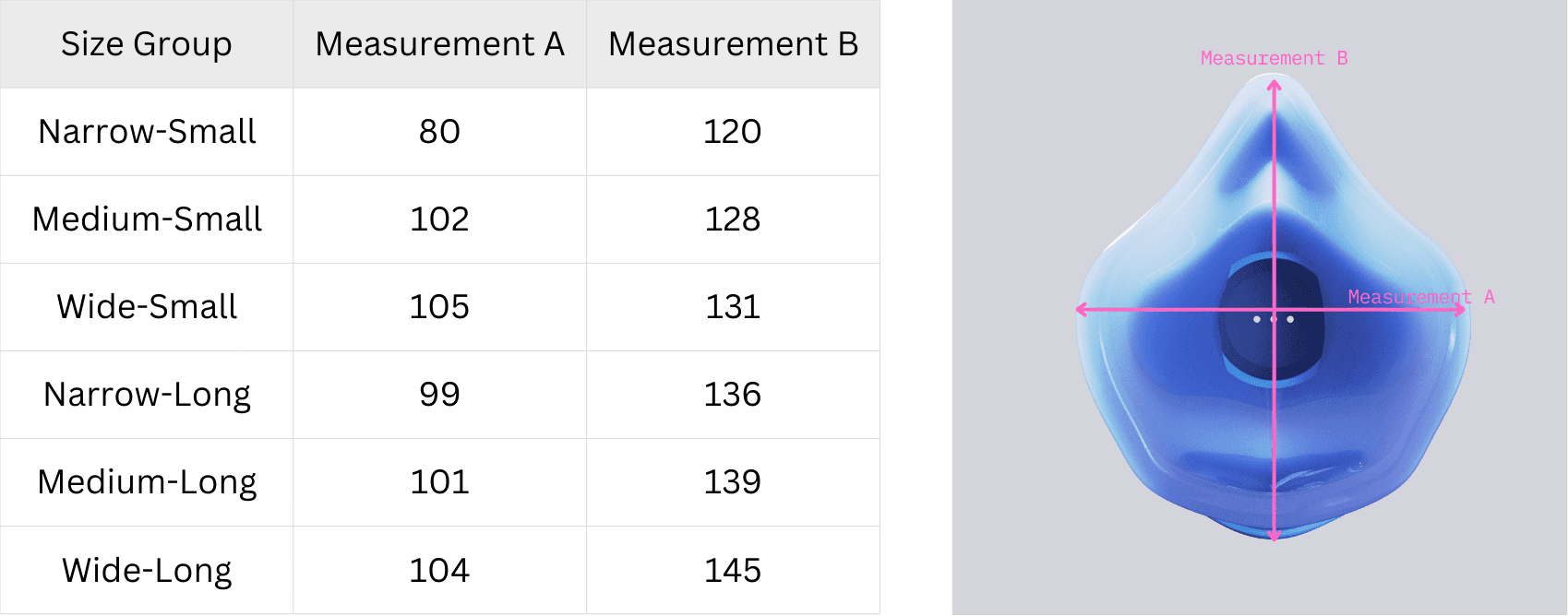
The New Sizing System

Validation of different size groups
Validation
The six sizes were first tested using digital fit simulations on 3D user models representing each target facial group. This confirmed mask-to-face conformity, seal coverage, and clearance for jaw movement in both horizontal (jaw width) and vertical (face height) dimensions
Edge-case and statistical checks
To stress-test coverage, four extreme “edge” personas from the largest group (Group 2) were evaluated to verify that even statistical outliers achieved an acceptable fit and seal. This confirmed that the transitions between adjacent sizes are smooth, with minimal gaps between groups.
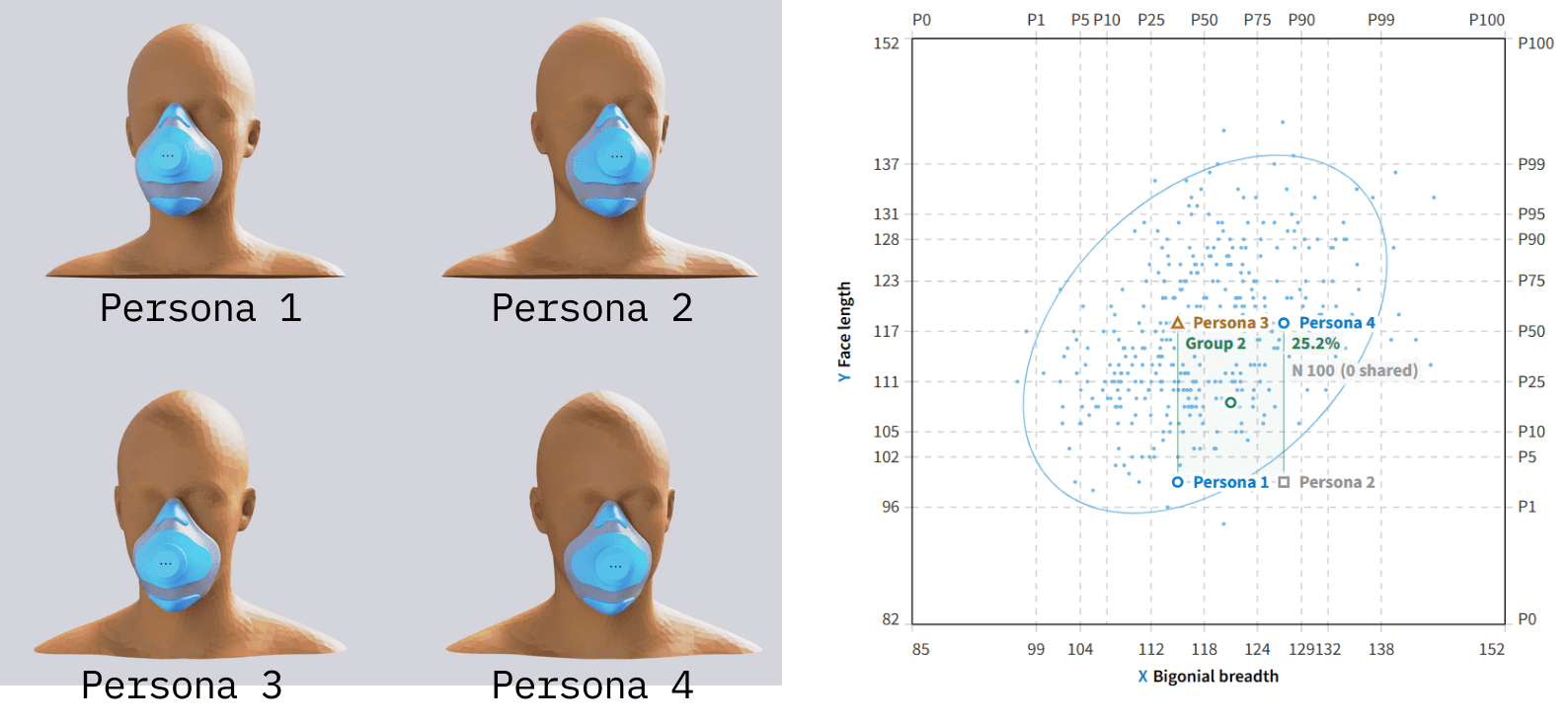
Validating the edge cases







